
Subscribe to My Newsletter
Hi! I’ve put together a selection of interview questions that I’ve been asked, and I’ve asked others myself when interviewing for a Java back-end software developer position. Enjoy! ;)
Data structures
What is the difference between Set and List?
List is a type of ordered collection while Set is a type of unordered collection.
List allows duplicates while Set doesn’t allow duplicate elements. All the elements of a Set should be unique if you try to insert the duplicate element in Set it would replace the existing value.
List permits any number of null values in its collection while Set permits only one null value in its collection.
What is the difference between ArrayList and LinkedList?
Criteria ArrayList LinkedList Internal Implementation ArrayList internally uses a dynamic array to store its elements. LinkedList uses Doubly Linked List to store its elements. Manipulation ArrayList is slow as array manipulation is slower. LinkedList is faster being node based as not much bit shifting required. Implementation ArrayList implements only List. LinkedList implements List as well as Queue. It can acts as a queue as well. Access ArrayList is faster in storing and accessing data. LinkedList is faster in manipulation of data. HashMap
How does the put() method of HashMap works in Java?
The put() method of HashMap works in the principle of hashing. It is responsible for storing an object into the backend array. The hashcode() method is used in conjunction with a hash function to find the correct location for the object into the bucket. If a collision occurs, then the entry object which contains both key and value is added to a linked list, and that linked list is stored into the bucket location.
What is the requirement for an object to be used as a key or value in HashMap?
The key or value object must implement the equals() and hashcode() method. The hash code is used when you insert the key object into the map while equals are used when you try to retrieve a value from the map.
Which data structure HashMap represents?
The HashMap is an implementation of hash table data structure.
Which data structure is used to implement HashMap in Java?
Even though HashMap represents a hash table, it is internally implemented by using an array and linked list data structure in JDK. The array data structure is used as a bucket, while a linked list is used to store all mappings which land in the same bucket. From Java 8 onwards, the linked list is dynamically replaced by binary search tree, once a number of elements in the linked list cross a certain threshold to improve performance.
How does resize happens in HashMap?
The resizing happens when the map becomes full or when the size of the map crosses the load factor. For example, if the load factor is 0.75 and then becomes more than 75% full, then resizing trigger, which involves an array copy. First, the size of the bucket is doubled, and then old entries are copied into a new bucket.
Common Data Structure Operations. Big-O time & space complexities.
Data Structure Time Complexity Space Complexity Average Worst Worst Access Search Insertion Deletion Access Search Insertion Deletion Array Θ(1) Θ(n) Θ(n) Θ(n) O(1) O(n) O(n) O(n) O(n) Stack Θ(n) Θ(n) Θ(1) Θ(1) O(n) O(n) O(1) O(1) O(n) Queue Θ(n) Θ(n) Θ(1) Θ(1) O(n) O(n) O(1) O(1) O(n) Singly-Linked List Θ(n) Θ(n) Θ(1) Θ(1) O(n) O(n) O(1) O(1) O(n) Doubly-Linked List Θ(n) Θ(n) Θ(1) Θ(1) O(n) O(n) O(1) O(1) O(n) Skip List Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) O(n) O(n) O(n) O(n) O(n log(n)) Hash Table N/A Θ(1) Θ(1) Θ(1) N/A O(n) O(n) O(n) O(n) Binary Search Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) O(n) O(n) O(n) O(n) O(n) Cartesian Tree N/A Θ(log(n)) Θ(log(n)) Θ(log(n)) N/A O(n) O(n) O(n) O(n) B-Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) Red-Black Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) Splay Tree N/A Θ(log(n)) Θ(log(n)) Θ(log(n)) N/A O(log(n)) O(log(n)) O(log(n)) O(n) AVL Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) KD Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) O(n) O(n) O(n) O(n) O(n) What is the difference between AVL and Red-Black Tree?
Criteria Red Black Trees AVL Trees Lookups Not that good at lookups (not strictly balanced) Better at lookups (strictly balanced) Color Yes, node either Red or Black (1 bit) No color Insertion and removal Faster insertion and removal operations as fewer rotations are done due to relatively relaxed balancing. Provide complex insertion and removal operations as more rotations are done due to relatively strict balancing. Storage 1 bit (color) Integer per node (heights storing) Searching Less efficient More efficient Balance Factor It does not gave balance factor Each node has a balance factor whose value will be 1,0,-1 Balancing Take less processing for balancing i.e.; maximum two rotation required Take more processing for balancing Used Used as an implementation of TreeMap and TreeSet in Java AVL trees are used in databases where faster retrievals and few inserts/deletes are required.
Algorithms
Describe binary search algorithm. Can we use binary search with LinkedList?
Binary Search is a searching algorithm used in a sorted array by repeatedly dividing the search interval in half. The idea of binary search is to use the information that the array is sorted and reduce the time complexity to O(Log n).
The basic steps to perform Binary Search are:
- Begin with the mid element of the whole array as a search key.
- If the value of the search key is equal to the item then return an index of the search key.
- Or if the value of the search key is less than the item in the middle of the interval, narrow the interval to the lower half.
- Otherwise, narrow it to the upper half.
- Repeatedly check from the second point until the value is found or the interval is empty.
No, it’s not effective to use binary search with LinkedList due to lack of random access in LinkedList.
Array Sorting Algorithms. Big-O time & space complexities.
Algorithm Time Complexity Space Complexity Best Average Worst Worst Quicksort Ω(n log(n)) Θ(n log(n)) O(n^2) O(log(n)) Mergesort Ω(n log(n)) Θ(n log(n)) O(n log(n)) O(n) Timsort Ω(n) Θ(n log(n)) O(n log(n)) O(n) Heapsort Ω(n log(n)) Θ(n log(n)) O(n log(n)) O(1) Bubble Sort Ω(n) Θ(n^2) O(n^2) O(1) Insertion Sort Ω(n) Θ(n^2) O(n^2) O(1) Selection Sort Ω(n^2) Θ(n^2) O(n^2) O(1) Tree Sort Ω(n log(n)) Θ(n log(n)) O(n^2) O(n) Shell Sort Ω(n log(n)) Θ(n(log(n))^2) O(n(log(n))^2) O(1) Bucket Sort Ω(n+k) Θ(n+k) O(n^2) O(n) Radix Sort Ω(nk) Θ(nk) O(nk) O(n+k) Counting Sort Ω(n+k) Θ(n+k) O(n+k) O(k) Cubesort Ω(n) Θ(n log(n)) O(n log(n)) O(n) What are the differences between QuickSort and MergeSort?
Criteria Quick Sort Merge Sort The partition of elements in the array The splitting of a array of elements is in any ratio, not necessarily divided into half. In the merge sort, the array is parted into just 2 halves (i.e. n/2). Worst case complexity O(n2) O(nlogn) Works well on Small arrays that fit in RAM It operates fine on any size of array Speed of execution It work faster than other sorting algorithms for small data set like Selection sort etc It has a consistent speed on any size of data Additional storage space requirement Less(In-place) More(not In-place) Efficiency Inefficient for larger arrays More efficient Sorting method Internal External Preferred for Arrays Linked Lists Cache locality good poor
Computer science
What is the difference between process and thread?
Criteria Process Thread Definition Process means a program execution. Thread means a segment of a process. Lightweight Not Lightweight. Lightweight. Termination time The process takes more time to terminate. The thread takes less time to terminate. Creation time It takes more time for creation. It takes less time for creation. Communication Needs more time compared to thread. Requires less time compared to processes. Ctx switching time More time for context switching. Less time for context switching. Resource Process consume more resources. Thread consume fewer resources. Treatment by OS Different process are tread separately by OS. All the level peer threads are treated as a single task by OS. Sharing The process is mostly isolated. Threads share memory adn resources (besides stack) What are the key differences between compiler and interpreter?
Basis of difference Compiler Interpreter Advantage The program code is already translated into machine code. Thus, it code execution time is less. Interpreters are easier to use, especially for beginners. Disadvantage You can’t change the program without going back to the source code. Interpreted programs can run on computers that have the corresponding interpreter. Machine code Store machine language as machine code on the disk Not saving machine code at all. Running time Compiled code run faster Interpreted code run slower Model It is based on language translation linking-loading model. It is based on Interpretation Method. Execution Program execution is separate from the compilation. It performed only after the entire output program is compiled. Program Execution is a part of Interpretation process, so it is performed line by line. Memory requirement Target program execute independently and do not require the compiler in the memory. The interpreter exists in the memory during interpretation. Code Optimization The compiler sees the entire code upfront. Hence, they perform lots of optimizations that make code run faster Interpreters see code line by line, and thus optimizations are not as robust as compilers Dynamic Typing Difficult to implement as compilers cannot predict what happens at turn time. Interpreted languages support Dynamic Typing Input It takes an entire program It takes a single line of code. Output Compliers generates intermediate machine code. Interpreter never generate any intermediate machine code. Errors Display all errors after, compilation, all at the same time. Displays all errors of each line one by one. What are the different layers of the OSI Model? At which OSI layer operates TCP/IP protocol?
Following are the different layers of the OSI Model:
- Physical layer
- Data Link Layer
- Network layer
- Transport layer
- Session layer
- Presentation layer
- Application layer
TCP operates at Transport level (4).
What are the key differences between TCP and UDP protocols?
Basis Transmission control protocol (TCP) User datagram protocol (UDP) Type of Service TCP is a connection-oriented protocol. Connection-orientation means that the communicating devices should establish a connection before transmitting data and should close the connection after transmitting the data. UDP is the Datagram-oriented protocol. This is because there is no overhead for opening a connection, maintaining a connection, and terminating a connection. UDP is efficient for broadcast and multicast types of network transmission. Reliability TCP is reliable as it guarantees the delivery of data to the destination router. The delivery of data to the destination cannot be guaranteed in UDP. Error checking mechanism TCP provides extensive error-checking mechanisms. It is because it provides flow control and acknowledgment of data. UDP has only the basic error checking mechanism using checksums. Acknowledgment An acknowledgment segment is present. No acknowledgment segment. Sequence Sequencing of data is a feature of Transmission Control Protocol (TCP). this means that packets arrive in order at the receiver. There is no sequencing of data in UDP. If the order is required, it has to be managed by the application layer. Speed TCP is comparatively slower than UDP. UDP is faster, simpler, and more efficient than TCP. Retransmission Retransmission of lost packets is possible in TCP, but not in UDP. There is no retransmission of lost packets in the User Datagram Protocol (UDP). Header Length TCP has a (20-60) bytes variable length header. UDP has an 8 bytes fixed-length header. Weight TCP is heavy-weight. UDP is lightweight. Handshaking Techniques Uses handshakes such as SYN, ACK, SYN-ACK It’s a connectionless protocol i.e. No handshake Broadcasting TCP doesn’t support Broadcasting. UDP supports Broadcasting. Protocols TCP is used by HTTP, HTTPs, FTP, SMTP and Telnet. UDP is used by DNS, DHCP, TFTP, SNMP, RIP, and VoIP. Can you explain the concept of recursion and name an example where you can use recursive function? What is tail recursion?
Recursion is a technique in computer programming where a function calls itself repeatedly until it reaches a base case that triggers the function to stop calling itself. In other words, a function calls itself to solve a smaller instance of the same problem, and this process continues until the base case is reached
Classic example - find factorial of the given number.
Tail recursion is a special case of recursion where the recursive call is the last operation performed in a function. In other words, the function’s result is calculated and returned after the recursive call has been made, without performing any additional operations.
This is significant because tail recursion can be optimized by some compilers or interpreters to use less memory, since the recursive call does not need to create a new stack frame for each call. Instead, the compiler or interpreter can reuse the same stack frame for each call, effectively turning the recursive algorithm into an iterative one.
Java
What is the Object class in Java? Can you name Object class methods?
The Object class is the parent class of all the classes in java by default. In other words, it is the topmost class of java.
Object’s methods:
Method Description public final Class getClass() returns the Class class object of this object. The Class class can further be used to get the metadata of this class. public int hashCode() returns the hashcode number for this object. public boolean equals(Object obj) compares the given object to this object. protected Object clone() throws CloneNotSupportedException creates and returns the exact copy (clone) of this object. Class have to implement Cloneable interface! public String toString() returns the string representation of this object. public final void notify() wakes up single thread, waiting on this object’s monitor. public final void notifyAll() wakes up all the threads, waiting on this object’s monitor. public final void wait(long timeout) throws InterruptedException causes the current thread to wait for the specified milliseconds, until another thread notifies (invokes notify() or notifyAll() method). public final void wait(long timeout,int nanos) throws InterruptedException causes the current thread to wait for the specified milliseconds and nanoseconds, until another thread notifies (invokes notify() or notifyAll() method). public final void wait() throws InterruptedException causes the current thread to wait, until another thread notifies (invokes notify() or notifyAll() method). protected void finalize() throws Throwable is invoked by the garbage collector before object is being garbage collected. In Java 9 finalize() method has been deprecated. What are equals() and hashCode() contracts and what is the contract between equals() and hashCode() methods?
equals() contract:
- reflexive: an object must be equal itself
- symmetric:
x.equals(y)must return the same result asy.equals(x) - transitive: if
x.equals(y)andy.equals(z), then alsox.equals(z) - consistent: the value of equals() should change only if a property that is contained in equals() changes (no randomness allowed)
a.equals(null)should return false.- comparing objects of different types should return false.
hashcode() contract:
- internal consistency: the value of hashCode() may only change if a property that is in equals() changes
- equals consistency: objects that are equal to each other must return the same hashCode
- collisions: unequal objects may have the same hashCode
You must override hashCode() in every class that overrides equals(). Failure to do so will result in a violation of the general contract for Object.hashCode(), which will prevent your class from functioning properly in conjunction with all hash-based collections, including HashMap, HashSet, and Hashtable.
What are the differences between primitive and non-primitive types?
The main difference between primitive and non-primitive data types are:
- Primitive types are predefined (already defined) in Java. Non-primitive types are created by the programmer and are not defined by Java (except for String).
- Non-primitive types can be used to call methods to perform certain operations, while primitive types cannot.
- A primitive type always has a value, while non-primitive types can be null.
- A primitive type starts with a lowercase letter, while a non-primitive type starts with an uppercase letter.
- The size of a primitive type depends on the data type, while non-primitive types have all the same size.
- Primitives are stored in the stack, while non-primitives are stored in the heap.
How does Java pass parameter variables (by reference or by value)?
In Java, we can only pass parameters by value.
Can you deduce what would be the output of the primitive type variable in the following code example?
public class PrimitiveByValueExample { public static void main(String... primitiveByValue) { int age = 30; changeAge(age); System.out.println(age); } static void changeAge(int age) { age = 35; } }Answer
If you determined that the value output would be 30, you are correct. It’s 30 because (again) Java passes object parameters by value. The number 30 is just a copy of the value, not the real value. Primitive types are allocated in the stack memory, so only the local value will be changed. In this case, there is no object reference.
Can you deduce what would be the output in the following code example?
public class ObjectReferenceExample { public static void main(String... args) { Human human = new Human(); changeName(human); System.out.println(human.name); } static void changeName(Human human) { human.name = "Artyom"; } } class Human { String name; }Answer
In this case, it will be Artyom! The reason is that Java object variables are simply references that point to real objects in the memory heap. Therefore, even though Java passes parameters to methods by value, if the variable points to an object reference, the real object will also be changed.
Can you deduce what would be the output in the following code example?
public class StringValueChange { public static void main(String... args) { String name = "BIBA"; changeName(name); System.out.println(name); } static void changeName(String name) { name = "boba"; } }Answer
If you guessed BIBA then congratulations! That happens because a String object is immutable, which means that the fields inside the String are final and can’t be changed.
Making the String class immutable gives us better control over one of Java’s most used objects. If the value of a String could be changed, it would create a lot of bugs. Also, note that we’re not changing an attribute of the String class; instead, we’re simply assigning a new String value to it. In this case, the “boba” value will be passed to name in the changeName method. The String “boba” will be eligible to be garbage collected as soon as the changeName method completes execution. Even though the initial object can’t be changed, the local variable will be.
Why does String class immutable and final in Java?
The String is Immutable in Java because String objects are cached in the String pool. Since cached String literals are shared between multiple clients there is always a risk where one client’s action would affect all other clients. Since caching of String objects was important for performance reasons this risk was avoided by making the String class Immutable.
At the same time, String was made final so that no one can compromise invariants of String class like Immutability, Caching, hashcode calculation, etc., by extending and overriding behaviors.
Multithreading
What are the two ways of implementing thread in Java?
- Extend the Thread class.
- Implement Runnable interface.
What's the difference between User thread and Daemon thread?
User Thread Daemon Thread JVM waits for user threads to finish their tasks before termination. JVM does not wait for daemon threads to finish their tasks before termination. These threads are normally created by the user for executing tasks concurrently. These threads are normally created by JVM. They are used for critical tasks or core work of an application. They are not used for any critical tasks but to do some supporting tasks. These threads are referred to as high-priority tasks, therefore are required for running in the foreground. These threads are referred to as low priority threads, therefore are especially required for supporting background tasks like garbage collection, releasing memory of unused objects, etc. What's the difference between User thread and Daemon thread?
User Thread Daemon Thread JVM waits for user threads to finish their tasks before termination. JVM does not wait for daemon threads to finish their tasks before termination. These threads are normally created by the user for executing tasks concurrently. These threads are normally created by JVM. They are used for critical tasks or core work of an application. They are not used for any critical tasks but to do some supporting tasks. These threads are referred to as high-priority tasks, therefore are required for running in the foreground. These threads are referred to as low priority threads, therefore are especially required for supporting background tasks like garbage collection, releasing memory of unused objects, etc. What is mutex? How to implement in Java?
In a multi-threaded application, to avoid a race condition, we need to synchronize access to the critical section. A mutex (or mutual exclusion) is the simplest type of synchronizer – it ensures that only one thread can execute the critical section of a computer program at a time. To access a critical section, a thread acquires the mutex, then accesses the critical section, and finally releases the mutex. In the meantime, all other threads block till the mutex releases.
Ways to implement:
- Synchronized - is the simplest way to implement a mutex in Java.
- ReentrantLock class
- Semaphore. Semaphore allows a fixed number of threads to access a critical section
Compare wait() and sleep() methods
Comparison criteria Wait Sleep Static method No Yes Defined in class Object Thread Should be called from syncronized context? Yes Not necessarily Should return the lock? Yes No Used for Inter-thread communication Stopping execution of the current thread notify()/notifyAll() method call effect Wakes up the thread No effect What’s the difference between notify() and notifyAll()?
notify(): It sends a notification and wakes up only a single thread instead of multiple threads that are waiting on the object’s monitor. notifyAll(): It sends notifications and wakes up all threads and allows them to compete for the object’s monitor instead of a single thread.
What is the difference between Runnable** and Callable Interface?
Runnable Interface Callable Interface It does not return any result and therefore, cannot throw a checked exception. It returns a result and therefore, can throw a checked exception. It was introduced in JDK 1.0. It was introduced in JDK 5.0, so one cannot use it before Java 5. It uses the run() method to define a task. It uses the call() method to define a task. What is the start() and run() method of Thread class?
start(): The start() method is used to start or begin the execution of a newly created thread. When the start() method is called, a new thread is created and this newly created thread executes the task that is kept in the run() method. You can call the start() method only once.
run(): The run() method is used to start or begin the execution of the same thread. When the run() method is called, no new thread is created as in the case of the start() method. This method is executed by the current thread. You can call the run() method multiple times.
What’s the purpose of the join() method?
join() method is generally used to pause the execution of a current thread unless and until the specified thread on which join is called is dead or completed.
Explain the meaning of the deadlock and when it can occur?
Deadlock, as the name suggests, is a situation where multiple threads are blocked forever. It generally occurs when multiple threads hold locks on different resources and are waiting for other resources to complete their task.
Explain volatile variables in Java
A volatile variable is basically a keyword that is used to ensure and address the visibility of changes to variables in multithreaded programming. This keyword cannot be used with classes and methods, instead can be used with variables. It is simply used to achieve thread-safety. If you mark any variable as volatile, then all the threads can read its value directly from the main memory rather than CPU cache, so that each thread can get an updated value of the variable.
What is busy waiting?
Busy-waiting is a technique in which one thread waits for some condition to happen, without calling wait() or sleep() methods and releasing the CPU. In this condition, one can pause a thread by making it run an empty loop for a certain time period, and it does not even give CPU control. Therefore, it is used to preserve CPU caches and avoid the cost of rebuilding cache.
What is the ExecutorService interface?
ExecutorService interface is basically a sub-interface of Executor interface with some additional methods or features that help in managing and controlling the execution of threads. It enables us to execute tasks asynchronously on threads.
Exceptions
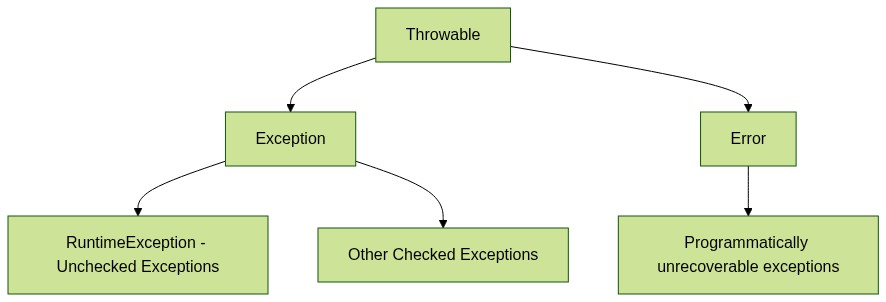
Can you describe Exception inheritance diagram?
What are the types of exceptions in Java? Explain them.
- Errors should identify programmatically unrecoverable problems (e.g. out of memory, stack overflow).
- Checked Exceptions should identify programmatically recoverable problems which are caused by unexpected conditions outside control of code (e.g. sql exception, file not found, class not found). To create such exception, you need to extend Exception class.
- Unchecked Exceptions should identify programmatically recoverable problems which are caused by faults in code flow (read: developer’s faults such as null pointer, illegal argument, array index out of bounds, etc). To create such exception, you need to extend RuntimeException class.
What are chained exceptions?
In an application, one exception throws many exceptions. i.e one exception causes another exception and that exception causes another exception thus forming chain of exceptions.
Do you know try-with-resources blocks? Why do we use them? When they are introduced?
Try-with-resources blocks are introduced from Java 7 to auto-close the resources like File I/O streams, Database connection, network connection etc… used in the try block. You need not to close the resources explicitly in your code. Try-with-resources implicitly closes all the resources used in the try block.
What are the legal combinations of try, catch and finally blocks?
- try/catch
- try/catch/finally
- try/finally
Can you name some of Java (8...) features?
Java 8:
- Lambdas Functional Interfaces
- Functional Interfaces
- Optionals/Streams
- Default and static methods in Interfaces
- New Concurrency API
- Java IO improvements
Java 9-11
- Collections helper methods such as
Set.of() - Private interface’s methods
- More Streams/Optionals features
- JShell
- HTTPClient
- Project JigSaw
Java 11-17
- New Switch statements
- Text-Blocks / Multiline Strings
- Records
- Sealed Classes
- Pattern Matching For InstanceOf
- New GC
Streams
What is the difference between Collection and Stream?
The main difference between a Collection and a Stream is that Collection contains its elements, but a Stream doesn’t. Stream work on a view where elements are actually stored by Collection or array, but unlike other views, any change made on Stream doesn’t reflect on the original Collection.
What is the difference between flatMap() and map() functions?
Even though both
map()andflatMap()can be used to transform one object to another by applying a method to each element.The main difference is that
flatMap()can also flatten the Stream. For example, if you have a list of the list, then you can convert it to a big list by using theflatMap()function.What is the difference between intermediate and terminal operations on Stream?
The intermediate Stream operation returns another Stream, which means you can further call other methods of Stream class to compose a pipeline.
For example after calling map() or flatMap() you can still call filter() method on Stream.
On the other hand, the terminal operation produces a result other than Streams like a value or a Collection.
Once a terminal method like forEach() or collect() is called, you cannot call any other method of Stream or reuse the Stream.
Are java 8 streams lazy? When they are evaluated?
Streams are lazy because intermediate operations are not evaluated until terminal operation is invoked. Each intermediate operation creates a new stream, stores the provided operation/function and return the new stream. The pipeline accumulates these newly created streams.
What is a functional interface? Can you name a few functional interfaces?
Functional interface is an interface that represents a function. Technically, an interface with just one abstract method is called a functional interface.
You can also use
@FunctionalInterfaceto annotated a functional interface. In that case, the compiler will verify if the interface actually contains just one abstract method.Another useful thing to know is that if a method accepts a functional interface, then you can pass a lambda expression to it.
Some examples of the functional interfaces:
- Consumer
- Predicate
- Supplier
- Function
- Runnable
- Callable
- Comparator
What is reflection? Name real-life examples.
Reflection is a feature in the Java programming language. It allows an executing Java program to examine or “introspect” upon itself, and manipulate internal properties of the program. For example, it’s possible for a Java class to obtain the names of all its members and display them.
Use-cases:
- Creating instances of classes: Reflection allows you to create instances of classes at runtime, which can be useful if you don’t know the class name until runtime.
- Inspecting and manipulating fields: Reflection can be used to inspect and manipulate the fields (variables) of a class at runtime. This can be useful if you need to access private fields or modify them dynamically.
- Invoking methods: Reflection can be used to invoke methods of a class at runtime. This can be useful if you don’t know the method name until runtime or if you want to call a private method.
- Dynamic proxy creation: Reflection can be used to create dynamic proxies, which are objects that intercept method calls and allow you to perform additional actions before or after the method is called. Dynamic proxies can be useful for implementing features like logging or security checks.
- Annotations processing: Reflection can be used to inspect and process annotations at runtime. This can be useful if you want to create custom annotations or if you need to access annotation information at runtime.
Hibernate
What is Hibernate?
Hibernate is a Java-based persistence framework and an object-relational mapping (ORM) framework that basically allows a developer to map POJO - plain old Java objects - to relational database tables.
What is a Session in Hibernate?
A session is an object that maintains the connection between Java object application and database. Session also has methods for storing, retrieving, modifying or deleting data from database using methods like persist(), load(), get(), update(), delete(), etc. Additionally, It has factory methods to return Query, Criteria, and Transaction objects.
What is a SessionFactory?
SessionFactory provides an instance of Session. It is a factory class that gives the Session objects based on the configuration parameters in order to establish the connection to the database. As a good practice, the application generally has a single instance of SessionFactory. The internal state of a SessionFactory which includes metadata about ORM is immutable.
This also provides the facility to get information like statistics and metadata related to a class, query executions, etc. It also holds second-level cache data if enabled.
What is lazy loading?
Lazy loading is mainly used for improving the application performance by helping to load the child objects on demand.
What is the difference between FetchMode and FetchType?
FetchMode defines how Hibernate will fetch the data (by select, join or subselect). FetchType, on the other hand, defines whether Hibernate will load data eagerly or lazily.
What is the difference between first level cache and second level cache?
Hibernate has 2 cache types. First level and second level cache for which the difference is given below:
First Level Cache Second Level Cache This is local to the Session object and cannot be shared between multiple sessions. This cache is maintained at the SessionFactory level and shared among all sessions in Hibernate. This cache is enabled by default and there is no way to disable it. This is disabled by default, but we can enable it through configuration. The first level cache is available only until the session is open, once the session is closed, the first level cache is destroyed. The second-level cache is available through the application’s life cycle, it is only destroyed and recreated when an application is restarted. What is the difference between get() and load() in Hibernate session?
get() load() This method gets the data from the database as soon as it is called. This method returns a proxy object and loads the data only when it is required. The database is hit every time the method is called. The database is hit only when it is really needed and this is called Lazy Loading which makes the method better. The method returns null if the object is not found. The method throws ObjectNotFoundException if the object is not found. This method should be used if we are unsure about the existence of data in the database. This method is to be used when we know for sure that the data is present in the database. Which constructor should always be present in the Entity Bean?
No-args constructor. Hibernate framework internally uses Reflection API for creating entity bean instances when get() or load() methods are called. The method Class.newInstance() is used which requires a no-args constructor to be present. When we don’t have this constructor in the entity beans, then hibernate fails to instantiate the bean and hence it throws HibernateException.
Can we declare the Entity class final?
No, we should not define the entity class final because hibernate uses proxy classes and objects for lazy loading of data and hits the database only when it is absolutely needed. This is achieved by extending the entity bean. If the entity class (or bean) is made final, then it cant be extended and hence lazy loading can not be supported.
What are the states of a persistent entity?
A persistent entity can exist in any of the following states:
Transient:
- This state is the initial state of any entity object.
- Once the instance of the entity class is created, then the object is said to have entered a transient state. These objects exist in heap memory.
- In this state, the object is not linked to any session. Hence, it is not related to any database due to which any changes in the data object don’t affect the data in the database.
Persistent:
- This state is entered whenever the object is linked or associated with the session.
- An object is said to be in a persistence state whenever we save or persist an object in the database. Each object corresponds to the row in the database table. Any modifications to the data in this state cause changes in the record in the database.
Detached:
- The object enters this state whenever the session is closed or the cache is cleared.
- Due to the object being no longer part of the session, any changes in the object will not reflect in the corresponding row of the database. However, it would still have its representation in the database.
- In case the developer wants to persist changes of this object, it has to be reattached to the hibernate session.
- In order to achieve the reattachment, we can use the methods load(), merge(), refresh(), update(), or save() methods on a new session by using the reference of the detached object.
Removed:
- Removed entities are persistent objects that have been passed to the session’s remove() method and soon will be deleted as soon as changes held in the session will be committed to the database.
What is N+1 SELECT problem in Hibernate? How to solve it?
N+1 SELECT problem is due to the result of using lazy loading and on-demand fetching strategy. If you have an N items list and each item from the list has a dependency on a collection of another object.
Some of the strategies followed for solving the N+1 SELECT problem are:
- Pre-fetch the records in batches which helps us to reduce the problem of N+1 to (N/K) + 1 where K refers to the size of the batch.
- Subselect the fetching strategy
- As last resort, try to avoid or disable lazy loading altogether.
What is the relation between Hibernate and JPA?
One is a specification (JPA), and the other is an implementation (Hibernate).
Spring
What are the main features of Spring Framework?
- Core technologies: IoC container, dependency injection, events, resources, i18n, validation, data binding, SpEL, AOP.
- Testing: mock objects, TestContext framework, Spring MVC Test, WebTestClient.
- Data Access: transactions, DAO support, JDBC, ORM, Marshalling XML, JPA.
- Spring MVC and Spring WebFlux web frameworks.
- Integration: remoting, JMS, JCA, JMX, email, tasks, scheduling, cache.
- Languages: Kotlin, Groovy, dynamic languages.
What do you mean by IoC (Inversion of Control) Container?
Spring container forms the core of the Spring Framework. The Spring container uses Dependency Injection (DI) for managing the application components by creating objects, wiring them together along with configuring and managing their overall life cycles. The instructions for the spring container to do the tasks can be provided either by XML configuration, Java annotations, or Java code.
What do you understand by Dependency Injection?
The main idea in Dependency Injection is that you don’t have to create your objects but you just have to describe how they should be created.
The components and services do not have to be connected by us in the code directly. We have to describe which services are needed by which components in the configuration file. The IoC container present in Spring will wire them up together.
In Java, the 3 ways of achieving dependency injection are:
- Constructor injection: The IoC container invokes the class constructor with a number of arguments where each argument represents a dependency on the other class.
- Setter injection: Spring container calls the setter methods on the beans after invoking a no-argument static factory method or default constructor to instantiate the bean.
- Field injection: Beans are getting injected into the field through reflection API. Field injection is deprecated.
What are Spring Beans?
Spring beans are Java POJO objects instantiated, configured, wired, and managed by Spring IoC container.
How is the configuration meta data provided to the spring container?
- XML-Based configuration.
- Annotation-Based configuration.
- Java-based configuration classes.
What are the bean scopes available in Spring?
- Singleton: The scope of bean definition while using this would be a single instance per IoC container.
- Prototype: Here, the scope for a single bean definition can be any number of object instances.
- Request: The scope of the bean definition is an HTTP request.
- Session: Here, the scope of the bean definition is HTTP-session.
- Global-session: The scope of the bean definition here is a Global HTTP session.
What are the features of Spring Boot?
- Production-ready auto configuration: Spring Boot auto-configuration attempts to automatically configure your Spring application based on the jar dependencies that you have added.
- Starter Dependencies: With the help of this feature, Spring Boot aggregates common dependencies together and eventually improves productivity and reduces the burden on.
- Spring Initializer: This is a web application that helps a developer in creating an internal project structure. The developer does not have to manually set up the structure of the project while making use of this feature.
- Out-of-box features: Such as, Spring Actuator, logging framework, security, etc
What is AOP?
Aspect-Oriented Programming (AOP) complements Object-Oriented Programming (OOP) by providing another way of thinking about program structure. The key unit of modularity in OOP is the class, whereas in AOP the unit of modularity is the aspect. Aspects enable the modularization of concerns such as transaction management that cut across multiple types and objects. (Such concerns are often termed crosscutting concerns in AOP literature.)
AOP concepts:
- Aspect: a modularization of a concern that cuts across multiple classes. Transaction management is a good example of a crosscutting concern in J2EE applications. In Spring AOP, aspects are implemented using regular classes
- Join point: a point during the execution of a program, such as the execution of a method or the handling of an exception. In Spring AOP, a join point always represents a method execution.
- Advice: action taken by an aspect at a particular join point. Different types of advice include “around,” “before” and “after” advice.
- Pointcut: a predicate that matches join points. Advice is associated with a pointcut expression and runs at any join point matched by the pointcut (for example, the execution of a method with a certain name). The concept of join points as matched by pointcut expressions is central to AOP, and Spring uses the AspectJ pointcut expression language by default.
Types of advice in Spring:
- Before advice: Advice that executes before a join point, but which does not have the ability to prevent execution flow proceeding to the join point (unless it throws an exception).
- After returning advice: Advice to be executed after a join point completes normally: for example, if a method returns without throwing an exception.
- After throwing advice: Advice to be executed if a method exits by throwing an exception.
- After (finally) advice: Advice to be executed regardless of the means by which a join point exits (normal or exceptional return).
- Around advice: Advice that surrounds a join point such as a method invocation. This is the most powerful kind of advice. Around advice can perform custom behavior before and after the method invocation. It is also responsible for choosing whether to proceed to the join point or to shortcut the advised method execution by returning its own return value or throwing an exception.
What is Spring security authentication and authorization?
Authentication: This refers to the process of verifying the identity of the user, using the credentials provided when accessing certain restricted resources. Two steps are involved in authenticating a user, namely identification and verification. An example is logging into a website with a username and a password. This is like answering the question
Who are you?Authorization: It is the ability to determine a user’s authority to perform an action or to view data, assuming they have successfully logged in. This ensures that users can only access the parts of a resource that they are authorized to access. It could be thought of as an answer to the question
Can a user do/read this?What are the differences between the annotations @Controller and @RestController?
You can say
@RestController = @Controller + @ResponseBody@Controller @RestController Mostly used traditional Spring MVC service. Represents RESTful web service in Spring. It is mostly used in Spring MVC service where model data needs to rendered using view. It is used in case of RESTful web service that returns object values bound to response body. If response values need to be converted through HttpMessageConverters and sent via response object, extra annotation @ResponseBody needs to be used on the class or the method handlers. The default behavior of the @RestController needs to be written on the response body because it is the combination of @Controller and @ResponseBody. @Controller provides control and flexibility over how the response needs to be sent. @RestController annotation has no such flexibility and writes all the results to the response body.
DBMS
What is meant by ACID properties in DBMS?
ACID stands for Atomicity, Consistency, Isolation, and Durability in a DBMS these are those properties that ensure a safe and secure way of sharing data among multiple users.
- Atomicity: This property ensures that the transaction is completed in all-or-nothing way.
- Consistency: This ensures that updates made to the database is valid and follows rules and restrictions.
- Isolation: This property ensures that each transaction is occurring independently of the others. This implies that the state of an ongoing transaction doesn’t affect the state of another ongoing transaction.
- Durability: This property ensures that the data is not lost in cases of a system failure or restart and is present in the same state as it was before the system failure or restart.
Can you name database isolation levels?
SQL standards state that the following three phenomena should be prevented whilst concurrent transactions. SQL standards define 4 levels of transaction isolations to deal with these phenomena.
Phenomena:
- Dirty reads: If a transaction reads data that is written due to concurrent uncommitted transaction, these reads are called dirty reads.
- Phantom reads: This occurs when two same queries when executed separately return different rows. For example, if transaction A retrieves some set of rows matching search criteria. Assume another transaction B retrieves new rows in addition to the rows obtained earlier for the same search criteria. The results are different.
- Non-repeatable reads: This occurs when a transaction tries to read the same row multiple times and gets different values each time due to concurrency. This happens when another transaction updates that data and our current transaction fetches that updated data, resulting in different values.
To tackle these, there are 4 standard isolation levels defined by SQL standards. They are as follows:
- Read Uncommitted – The lowest level of the isolations. Here, the transactions are not isolated and can read data that are not committed by other transactions resulting in dirty reads.
- Read Committed – This level ensures that the data read is committed at any instant of read time. Hence, dirty reads are avoided here. This level makes use of read/write lock on the current rows which prevents read/write/update/delete of that row when the current transaction is being operated on.
- Repeatable Read – The most restrictive level of isolation. This holds read and write locks for all rows it operates on. Due to this, non-repeatable reads are avoided as other transactions cannot read, write, update or delete the rows.
- Serializable – The highest of all isolation levels. This guarantees that the execution is serializable where execution of any concurrent operations are guaranteed to be appeared as executing serially.
The following table explains which isolation level protected from which phenomena (’-’ - not possible, ‘+’ - possible):
Isolation levels Dirty Reads Non-Repeatable Reads Phantom Reads Read Uncommitted + + + Read Committed - + + Repeatable Read - - + Serializable - - - What are different types of relationships amongst tables in a DBMS?
- One to One Relationship: This type of relationship is applied when a particular row in table X is linked to a singular row in table Y.
- One to Many Relationship: This type of relationship is applied when a single row in table X is related to many rows in table Y.
- Many to Many Relationship: This type of relationship is applied when multiple rows in table X can be linked to multiple rows in table Y.
- Self Referencing Relationship: This type of relationship is applied when a particular row in table X is associated with the same table.
What is a lock? Explain the major difference between a shared lock and an exclusive lock during a transaction in a database.
A database lock is a mechanism to protect a shared piece of data from getting updated by two or more database users at the same time. When a single database user or session has acquired a lock then no other database user or session can modify that data until the lock is released.
Shared Lock: A shared lock is required for reading a data item and many transactions may hold a lock on the same data item in a shared lock. Multiple transactions are allowed to read the data items in a shared lock.
Exclusive lock: An exclusive lock is a lock on any transaction that is about to perform a write operation. This type of lock doesn’t allow more than one transaction and hence prevents any inconsistency in the database.
What is meant by normalization and denormalization?
Normalization is a process of reducing redundancy by organizing the data into multiple tables. Normalization leads to better usage of disk spaces and makes it easier to maintain the integrity of the database.
Denormalization is the reverse process of normalization as it combines the tables which have been normalized into a single table so that data retrieval becomes faster. JOIN operation allows us to create a denormalized form of the data by reversing the normalization.
Can you explain 3 Normalization forms in a DBMS?
- 1NF:
- Every column must have a single value and should be atomic.
- Each record should be unique.
- 2NF:
- The table should be in its 1NF i.e. satisfy all the conditions of 1NF.
- Every non-prime attribute of the table should be fully functionally dependent on the primary key.
- 3NF:
- The table should be in its 2NF i.e. satisfy all the conditions of 2NF.
- Has no transitive functional dependencies. A transitive functional dependency is when changing a non-key column, might cause any of the other non-key columns to change.
- 1NF:
What are Constraints in SQL?
Constraints are used to specify the rules concerning data in the table. It can be applied for single or multiple fields in an SQL table during the creation of the table or after creating using the ALTER TABLE command. The constraints are:
- NOT NULL - Restricts NULL value from being inserted into a column.
- CHECK - Verifies that all values in a field satisfy a condition.
- DEFAULT - Automatically assigns a default value if no value has been specified for the field.
- UNIQUE - Ensures unique values to be inserted into the field.
- INDEX - Indexes a field providing faster retrieval of records.
- PRIMARY KEY - Uniquely identifies each record in a table.
- FOREIGN KEY - Ensures referential integrity for a record in another table.
What is a Join? Can you name join types?
There are 5 different types of JOINs in SQL:
- (INNER) JOIN: Retrieves records that have matching values in both tables involved in the join.
- LEFT (OUTER) JOIN: Retrieves all the records/rows from the left and the matched records/rows from the right table.
- RIGHT (OUTER) JOIN: Retrieves all the records/rows from the right and the matched records/rows from the left table.
- FULL (OUTER) JOIN: Retrieves all the records where there is a match in either the left or right table.
- CROSS JOIN: Can be defined as a cartesian product of the two tables included in the join. If table X has N rows and table Y has M rows, then the result of cross join would be NxM rows.
What is an Index? Explain the difference between Unique/Non-unique and Clustered/Non-clustered index.
A database index is a data structure that provides a quick lookup of data in a column or columns of a table. It enhances the speed of operations accessing data from a database table at the cost of additional writes and memory to maintain the index data structure.
- Unique vs Non-Unique Index:
- Unique indexes are indexes that help maintain data integrity by ensuring that no two rows of data in a table have identical key values. Once a unique index has been defined for a table, uniqueness is enforced whenever keys are added or changed within the index.
- Non-unique indexes, on the other hand, are not used to enforce constraints on the tables with which they are associated. Instead, non-unique indexes are used solely to improve query performance by maintaining a sorted order of data values that are used frequently.
- Clustered vs Non-Clustered Index
- Clustered index modifies the way records are stored in a database based on the indexed column. A non-clustered index creates a separate entity within the table which references the original table.
- Clustered index is used for easy and speedy retrieval of data from the database, whereas, fetching records from the non-clustered index is relatively slower.
- In SQL, a table can have a single clustered index whereas it can have multiple non-clustered indexes.
- Unique vs Non-Unique Index:
Can you tell what SQL injection is ?
Insertion or ‘Injection’ of some SQL Query from the input data of the client to the application is called SQL Injection. They can perform CRUD operations on the database and can lead to vulnerabilities and loss of data.
It can occur in 2 ways:
- Data is used to dynamically construct an SQL Query.
- Unintended data from an untrusted source enters the application.
NoSQL
What are NoSQL databases? What are the different types of NoSQL databases?
A NoSQL database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.
Types of NoSQL databases:
- Document Oriented (e.g. Mongo)
- Key Value (e.g. Redis Memcached, Amazon DynamoDb)
- Graph (e.g. Neo4j)
- Column Oriented (e.g. Apache Hbase,)
What are the advantages of NoSQL over traditional RDBMS?
NoSQL is better than RDBMS because of the following reasons/properties of NoSQL:
- It supports semi-structured data and volatile data
- It does not have schema
- Read/Write throughput is very high
- Horizontal scalability can be achieved easily
- Will support Bigdata in volumes of Terra Bytes & Peta Bytes
- Provides good support for Analytic tools on top of Bigdata
- Can be hosted in cheaper hardware machines
- In-memory caching option is available to increase the performance of queries
- Faster development life cycles for developers
Still, RDBMS is better than NoSQL for the following reasons/properties of RDBMS:
- Transactions with ACID properties - Atomicity, Consistency, Isolation & Durability
- Adherence to Strong Schema of data being written/read
- Real time query management ( in case of data size < 10 Tera bytes )
- Execution of complex queries involving join & group by clauses
Explain difference between scaling horizontally and vertically for databases.
Horizontal scaling means that you scale by adding more machines into your pool of resources whereas Vertical scaling means that you scale by adding more power (CPU, RAM) to an existing machine.
What is Sharding?
Sharding is a method for distributing data across multiple machines. NoSQL data storages are often achieve horizontal scaling through sharding.
What is BASE acronym stands for?
The rise in popularity of NoSQL databases provided a flexible and fluidity with ease to manipulate data and as a result, a new database model was designed, reflecting these properties - BASE.
- Basically Available – Rather than enforcing immediate consistency, BASE-modelled NoSQL databases will ensure availability of data by spreading and replicating it across the nodes of the database cluster.
- Soft State – Due to the lack of immediate consistency, data values may change over time. The BASE model breaks off with the concept of a database which enforces its own consistency, delegating that responsibility to developers.
- Eventually Consistent – The fact that BASE does not enforce immediate consistency does not mean that it never achieves it. However, until it does, data reads are still possible (even though they might not reflect the reality).
ElasticSearch
What is ElasticSearch?
Elasticsearch is a modern, distributed, and analytics search engine that is based or built on Apache Lucene. ElasticSearch enables you to store, search, and analyze vast or huge amounts of data in near real-time, providing results in milliseconds. Elasticsearch, one of the pillars of the Elastic Stack, is a free and open collection of tools for ingesting, storing, enriching, analyzing, and visualizing data. The latency between the time a document is indexed and the moment it can be searched is extremely short with ElasticSearch. As opposed to most NoSQL databases, Elasticsearch NoSQL focuses more on search capabilities and provides a rich HTTP RESTful API that allows for fast searches in near real-time. Developed in Java, ElasticSearch is an open-source search engine that has been used by many large organizations around the globe since it was released in 2010.
What are ElasticSearch use-cases?
- Application search, Enterprise search, and Website search.
- Analyzing log data in near-real-time and on a scalable basis.
- Business analytics and security analytics.
- Analysis and visualization of geospatial data.
- Monitoring the performance of applications, infrastructure metrics and containers.
What is ElasticSearch Mapping? What are types of mapping in ES?
ElasticSearch mappings define how documents and their fields are indexed and stored in ElasticSearch databases or ElasticSearch DBs. This defines the types and formats of the fields that appear in the documents. As a result, mapping can have a significant impact on how Elasticsearch searches for and stores data. After creating an index, we must define the mapping. An incorrect preliminary definition and mapping might lead to incorrect search results.
Mapping types:
- Static mapping: Users perform static mappings when they create an index.
- Dynamic mapping: Elasticsearch automatically creates dynamic mappings at runtime depending on the input.
What is ElasticSearch fuzzy search?
With fuzzy search, you can find documents with terms similar to your search term based on a Levenshtein edit distance measure. Edit distance is essentially the number of single-character changes or edits required to change one term into another.
What is document, index in ES?
Document refers to a unit of information that can be indexed. Each index within Elasticsearch contains multiple documents. Documents are written in JavaScript Object Notation (JSON), which is a widely used format for internet data exchange. Documents are composed of fields, and each field has its own type of data.
Think of it like:
- ES Index like Table in SQL
- ES Document like Row in SQL
- ES Field like Column in SQL
What are tokenizers and analyzers in ES?
Tokenizer receives a stream of characters (text), tokenizes them (usually by breaking them up into individual words or tokens), and outputs the stream of words/tokens.
Analyzer analyzes data at indexing time indicating how text should be indexes and searched in ES.
What is an Inverted index in ElasticSearch?
ElasticSearch utilizes a hashmap-like data structure known as an inverted index that allows for rapid full-text searches. The inverted index lists all the unique words that appear in one or more documents and identifies all the documents those words appear in. With it, you can conduct quick searches across millions of documents to find relevant data.
Message Queues & Brokers
What is a message broker?
A message broker is software that enables applications, systems, and services to communicate with each other and exchange information.
Message brokers can validate, store, route, and deliver messages to the appropriate destinations. They serve as intermediaries between other applications, allowing senders to issue messages without knowing where the receivers are, whether or not they are active, or how many of them there are. This facilitates decoupling of processes and services within systems.
In order to provide reliable message storage and guaranteed delivery, message brokers often rely on a substructure or component called a message queue that stores and orders the messages until the consuming applications can process them. In a message queue, messages are stored in the exact order in which they were transmitted and remain in the queue until receipt is confirmed.
Asynchronous messaging refers to the type of inter-application communication that message brokers make possible. It prevents the loss of valuable data and enables systems to continue functioning even in the face of the intermittent connectivity or latency issues common on public networks.
Compare RabbitMQ and Apache Kafka.
Parameter RabbitMQ Kafka Performance Up to 10K messages per second Up to 1 million messages per second Synchronicity of messages Can be synchronous/asynchronous Durable message store that can replay messages Topology Exchange queue type: Direct, Fan out, Topic, Header-based Publish/subscribe based Payload Size No constraints Default 1MB limit Usage Cases Simple use cases Massive data/high throughput cases Data Flow Distinct bounded data packets in the form of messages Unbounded continuous data in the form of key-value pairs. Data Unit Message Continuous stream Data Tracking Broker/Publisher keeps track of message status (read/unread) Broker/Publisher keeps only unread messages; it doesn’t retain sent messages. Routing messages Complex routing is possible based on event types Complex routing is not possible; however, we can subscribe to individual topics. Message delivery system Message pushed to specific queues Pull-based model; consumer pulls messages as required Message management Prioritize messages Order/Retain/Guarantee messages Message Retention Acknowledgment based Policy-based (e.g., ten days) Event storage structure Queue Logs Consumer Queues Decoupled Consumer queues Coupled consumer to partition/groups Kafka
What are the major components of Kafka?
- Topic
- Consumer
- Producer
- Broker
What are 4 Kafka API components?
- Producer API: The Producer API in Kafka allows an application to publish a stream of records to one or more Kafka topics.
- Consumer API: An application can subscribe to one or more Kafka topics using the Kafka Consumer API. It also enables the application to process streams of records generated in relation to such topics.
- Streams API: The Kafka Streams API allows an application to use a stream processing architecture to process data in Kafka. An application can use this API to take input streams from one or more topics, process them using streams operations, and generate output streams to transmit to one or more topics.
- Connect API: The Kafka Connector API connects Kafka topics to applications. A connector, for example, may capture all database updates and ensure that they are made available in a Kafka topic.
What are partitions in Kafka?
Kafka topics are separated into partitions, each of which contains records in a fixed order. A unique offset is assigned and attributed to each record in a partition. Multiple partition logs can be found in a single topic. This allows several users to read from the same topic at the same time. Topics can be parallelized via partitions, which split data into a single topic among numerous brokers.
Replication in Kafka is done at the partition level. A replica is the redundant element of a topic partition. Each partition often contains one or more replicas, which means that partitions contain messages that are duplicated across many Kafka brokers in the cluster.
One server serves as the leader of each partition (replica), while the others function as followers. The leader replica is in charge of all read-write requests for the partition, while the followers replicate the leader. If the lead server goes down, one of the followers takes over as the leader. To disperse the burden, we should aim for a good balance of leaders, with each broker leading an equal number of partitions.
What is a partition key in Kafka?
In Kafka terminology, messages are referred to as records. Each record has a key and a value, with the key being optional. For record partitioning, the record’s key is used. There will be one or more partitions for each topic. Kafka producer uses the record’s key to determine which partition the record should be written to. The producer will always choose the same partition for two records with the same key.
Web
What is OAuth2?
OAuth 2.0, permits client applications to access protected resources via an authorization server. Using it, a client application (third party) can gain limited access to an HTTP service on behalf of the resource owner or on its own behalf.
What is JWT?
JWT (JSON Web Tokens) are tokens that are generated by a server upon user authentication in a web application and are then sent to the client (normally a browser). As a result, these tokens are sent on every HTTP request, allowing the server to verify or authenticate the user’s identity. This method is used for authorizing transactions or requests between client and server. The use of JWT does not intend to hide data, but rather ensure its authenticity. JWTs are signed and encoded, instead of encrypted. A cryptographic algorithm is used to digitally sign JWTs in order to ensure that they cannot be altered after they are issued. Information contained in the token is signed by the server’s private key in order to ensure integrity.
Token exchange flow:
- Login credentials are sent by the user. When successful, JWT tokens (signed by private key/secret key) are sent back by the server to the client.
- The client takes JWT and inserts it in the Authorization header to make data requests for the user.
- Upon receiving the token from the client, the server simply needs to compare the signature sent by the client to the one it generated with its private key/secret key. The token will be valid once the signatures match.
Three parts make up JSON Web Tokens, separated by a dot (.). The first two (the header and the payload) contain Base64-URL encoded JSON, while the third is a cryptographic signature.
What are the features of RESTful Web Services?
The service is based on the Client-Server model. The service uses HTTP Protocol for fetching data/resources, query execution, or any other functions. Resources are accessible to the service by means of URIs. It follows the statelessness concept where the client request and response (client state is not maintained on the server). These services also use the concept of caching to minimize the server calls for the same type of repeated requests.
What is the difference between idempotent and safe HTTP methods?
- Safe methods are those that do not change any resources internally. These methods can be cached and can be retrieved without any effects on the resource.
- Idempotent methods are those methods that do not change the responses to the resources externally. They can be called multiple times without any change in the responses.
Following table describes what methods are idempotent and what are safe:
HTTP Methods Idempotent Safe OPTIONS yes yes GET yes yes HEAD yes yes PUT yes no POST no no DELETE yes no PATCH no no What are the differences between WebSocket and REST?
Criteria REST Web Socket Stateless Yes, REST follows stateless architecture, meaning it won’t store any session-based data. No, Web Socket APIs follow the stateful protocol as it necessitates session-based data storage. Communication The mode of communication is uni-directional. At a time, only the server or the client will communicate. The communication is bi-directional, communication can be done by both client or server at a time. Model REST is based on the Request-Response Model. Web Socket follows the full-duplex model. Connection For every HTTP request, a new TCP connection is set up. There will be only one TCP connection and then the client and server can start communicating. Scaling REST web services support both vertical and horizontal scaling. Web socket-based services only support vertical scaling. Speed Communication is slower here. Message transmission happens very faster than REST API. Memory/Buffers Memory/Buffers are not needed to store data here. Memory is required to store data. What would be the use-cases of using REST, gRPC, GraphQL, Web Socket technologies?
- REST use-cases:
- You’re building a CRUD-style web application.
- Your API is mostly manipulating well-structured related data.
- Your API needs to be highly cacheable, including support for intermediate proxy caching.
- gRPC use-cases:
- Your API is private and powers communications between parts of a microservices architecture.
- Your API is mostly about actions.
- You need to collect data from IoT devices.
- You’re implementing a Backend For Frontend pattern.
- Performance is a critical requirement (due to the tight packing of the Protocol Buffers and the use of HTTP/2).
- GraphQL use-cases:
- You’re building a public API and you want it to be highly flexible in terms of customizing requests.
- You want to defer defining your API surface until you have a chance to analyze which resources your clients tend to request.
- You want to aggregate internal data from multiple sources into a public API for multiple clients with varying data requirements.
- You want to save bandwidth.
- Web Socket use cases:
- Realtime updates, where the communication is unidirectional, and the server is streaming low-latency (and often frequent) updates to the client. Think of live score updates, newsfeeds, alerts, and notifications, to name just a few use cases.
- Bidirectional communication, where both the client and the server send and receive messages. Examples include chat, virtual events, and virtual classrooms (the last two usually involve features like live polls, quizzes, and Q&As). WebSockets can also be used to underpin multi-user synchronized collaboration functionality, such as multiple people editing the same document simultaneously.
- Fanning out (broadcasting) the same message to multiple users at once. Various WebSocket libraries implement broadcasting over WebSockets (usually via pub/sub messaging). In contrast, gRPC does not natively support broadcasting.
- REST use-cases:
Architectures/Microservices
What are Microservices?
Microservices, also known as Microservices Architecture, is basically an SDLC approach in which large applications are built as a collection of small functional modules. It is one of the most widely adopted architectural concepts within software development. In addition to helping in easy maintenance, this architecture also makes development faster. Additionally, microservices are also a big asset for the latest methods of software development such as DevOps and Agile. Furthermore, it helps deliver large, complex applications promptly, frequently, and reliably.
Applications are modeled as collections of services, which are:
- Maintainable and testable
- Loosely coupled
- Independently deployable
- Designed or organized around business capabilities
- Managed by a small team
Compare Monolithic, SOA, Microservice architectures
Microservices, Monolith, and Service-Oriented Architecture (SOA) are three different architectural styles used to build software applications. While all three approaches aim to provide the same fundamental functionality of building software, each of them has unique characteristics, benefits, and drawbacks.
Monolithic Architecture:
Monolithic architecture refers to a single, unified application that is developed as a single codebase and deployed as a single unit. All components of the application are tightly coupled and share the same database. Changes to any part of the application require a complete rebuild, retesting, and redeployment of the entire application.
Advantages of Monolithic Architecture:
- It’s simple to develop and deploy.
- Easier to maintain for small applications
- Performance is good when there is a small number of users.
Disadvantages of Monolithic Architecture:
- Scaling is difficult.
- Difficult to maintain for large and complex applications.
- The entire application has to be rebuilt, tested and redeployed for any changes.
Service-Oriented Architecture (SOA):
SOA is an architectural style that involves building software applications as a collection of loosely coupled services. These services communicate with each other through standard protocols such as HTTP or message queues. Each service has its own database, and the data is shared between services through APIs.
Advantages of SOA:
- Services are decoupled, which means changes in one service don’t affect other services.
- Easy to scale individual services.
- Easier to maintain as services can be updated without affecting the entire application.
Disadvantages of SOA:
- Complex to design and implement.
- Can lead to performance issues as multiple services are involved.
Microservices Architecture:
Microservices architecture is an extension of the SOA approach. It involves building software applications as a collection of small, independent services that are loosely coupled and independently deployable. Each service has its own database, and communication between services is done through APIs.
Advantages of Microservices Architecture:
- Services are highly decoupled, which makes them easier to manage and maintain.
- Easier to scale individual services.
- Enables faster and independent deployment of services.
- Better fault isolation, as problems in one service don’t affect other services.
Disadvantages of Microservices Architecture:
- More complex to design and implement than monolithic or SOA architectures.
- Requires additional infrastructure and overhead to manage the individual services.
In conclusion, each architectural style has its unique characteristics and tradeoffs. While monolithic architecture is simple and easy to deploy, it’s difficult to scale and maintain for large and complex applications. SOA provides a more flexible and scalable approach, but it’s complex to design and implement. Microservices architecture is highly decoupled and provides faster deployment and fault isolation, but it requires additional infrastructure and is complex to design and implement.
What are the main patterns of Microservices?
- Containers, Clustering, and Orchestration
- IaC (Infrastructure as Code Concept)
- Cloud Infrastructure
- SAGA (Choreography vs Orchestration)
- Event sourcing
- CQRS
- API Gateway
- Load Balancing
- Circuit Breaker
- CI/CD
What are the benefits and drawbacks of Microservices?
Benefits:
- Self-contained, and independent deployment module.
- Independently managed services.
- It is easier to test and has fewer dependencies.
- A greater degree of scalability and agility.
- Simplicity in debugging & maintenance.
- Better communication between developers and business.
- Development teams of a smaller size.
Drawbacks:
- Due to the complexity of the architecture, testing and monitoring are more difficult.
- Pre-planning is essential.
- Complex development.
- Expensive compared to monoliths.
- Security implications.
- Maintaining the network is more difficult.
How do microservices interact with each other?
There are two main ways services can interact with each other:
- Synchronously: HTTP/REST with JSON or binary protocol for request-response, Websockets for streaming
- Asynchronously: Through a broker or server program that uses advanced routing algorithms. Such as, Kafka, RabbitMQ, AWS SNS, AWS SQS, etc.
What does Distributed Transaction mean? What are the implementation methods?
A microservice, from its core principles and in its true context, is a distributed system. A transaction is distributed to multiple services that are called sequentially or parallelly to complete the entire transaction. With a microservices architecture, the most common pattern is database per microservice, so transactions also need to span across different databases.
Implementation methods:
- Two-phase commit (2PC):
Two-phase commit is a well known pattern in database systems. In a two-phase commit, there is a controlling node that houses most of the logic and participating nodes (microservices) on which the actions are performed. It works in two phases:
- Prepare phase (Phase 1): The controlling node asks all of the participating nodes if they are ready to commit. The participating nodes respond with yes or no.
- Commit phase (Phase 2): If all of the nodes replied in the affirmative, then the controlling node asks them to commit. Even if one node replies in the negative, the controlling node asks them to roll back.
- Saga:
- Choreography
In the Saga choreography pattern, each individual microservice that is part of a process publishes an event that is picked up by the successive microservice.
- Orchestration
As the name of the Saga orchestration pattern suggests, there is a single orchestrator component that is responsible for managing the overall process flow.
- Choreography
In a microservices world where each microservice has its own data store, it is complex and difficult to keep the consistency of data. Even though 2PC can help provide transaction management in a distributed system, it also becomes the single point of failure as the onus of a transaction falls onto the coordinator. With the number of phases, the overall performance is also impacted. Because of the chattiness of the coordinator, the whole system is bound by the slowest resources since any ready node has to wait for confirmation from a slower node. Also, typical implementations of such a coordinator are synchronous in nature, which can lead to a reduced throughput in the future. Saga is one of the best ways to implement BASE transactions and ensure the eventual consistency of the data in a distributed architecture.
- Two-phase commit (2PC):
What are the main types of Microservices testing?
Test types:
- Unit tests: This type of testing helps you validate the performance of each component (or unit) of your software.
- Contract tests: To ensure that services can communicate, a contract defines the results or outputs expected for specific inputs. The service itself remains a black box.
- Integration tests: An integration test collects microservices and tests them together as a subsystem. The goal is to verify that the microservices collaborate to achieve a common goal.
- End-To-End Testing: The main goal of an end-to-end test is to verify that the entire application works to achieve its business use-cases. During end-to-end testing, the application is treated as a black box while tests exercise the system as it is fully deployed. For example, testing on a stage.
What are the roles of Docker/Kubernetes in microservice architecture?
Docker allows to package application along with their dependencies as portable, self-sufficient and independent Docker containers. Later on these containers can be deployed on servers independently from each other.
While Docker facilitates the process of packaging and distributing contained apps, as applications scale more containers need to be deployed across multiple servers, adding complexity. This can result in the following issues:
- Coordination and scheduling of many containers becomes a challenge
- Different containers in the app need to talk to each other, and this could lead to errors
- Scaling up many container instances also results in bottlenecks
Kubernetes, the open-source container-orchestration software, comes to the rescue here. It can help by allowing APIs to control the way the Docker containers and workloads are managed.
The containers, after being grouped into pods (which is the basic operational unit for Kubernetes), are scheduled to run on a cluster of virtual machines that are orchestrated, and the available are computed and are allocated appropriately. This allows the containers and pods to be scaled as needed and ensures the app is up and running at all times.
While Docker has a comparable orchestration technology called Docker Swarm for clustering Docker containers, it is tightly integrated into the Docker ecosystem, uses its own API, and runs on a single node. Kubernetes, on the other hand, runs across a cluster, is more extensive, and can efficiently coordinate clusters of nodes at scale.
Patterns, designs & principles
What are GoF (Gang of Four) patterns?
- Creational Design Patterns
- Builder. Uses to create complex objects.
- Abstract Factory. Allows the creation of objects without specifying their concrete type.
- Factory Method. Creates objects without specifying the exact class to create.
- Prototype. Creates a new object from an existing object.
- Singleton. Ensures only one instance of an object is created.
- Structural Design Patterns
- Adapter. Allows for two incompatible classes to work together by wrapping an interface around one of the existing classes.
- Bridge. Decouples an abstraction so two classes can vary independently.
- Composite. Takes a group of objects into a single object.
- Decorator. Allows for an object’s behavior to be extended dynamically at run time.
- Facade. Provides a simple interface to a more complex underlying object.
- Flyweight. Reduces the cost of complex object models.
- Proxy. Provides a placeholder interface to an underlying object to control access, reduce cost, or reduce complexity.
- Behavior Design Patterns
- Chain of Responsibility. Delegates commands to a chain of processing objects.
- Command. Creates objects which encapsulate actions and parameters.
- Strategy. Allows one of a family of algorithms to be selected on-the-fly at run-time.
- Interpreter. Implements a specialized language.
- Iterator. Accesses the elements of an object sequentially without exposing its underlying representation.
- Mediator. Allows loose coupling between classes by being the only class that has detailed knowledge of their methods.
- Memento. Provides the ability to restore an object to its previous state.
- Observer. Is a publish/subscribe pattern which allows a number of observer objects to see an event.
- State. Allows an object to alter its behavior when its internal state changes.
- Template Method. Defines the skeleton of an algorithm as an abstract class, allowing its sub-classes to provide concrete behavior.
- Visitor. Separates an algorithm from an object structure by moving the hierarchy of methods into one object.
- Creational Design Patterns
SOLID principles
SOLID is an acronym for the first five object-oriented design (OOD) principles by Robert C. Martin (also known as Uncle Bob).**
These principles establish practices that lend to developing software with considerations for maintaining and extending as the project grows. Adopting these practices can also contribute to avoiding code smells, refactoring code, and Agile or Adaptive software development.
- S - Single-responsiblity Principle. A class should have one and only one reason to change, meaning that a class should have only one job.
- O - Open-closed Principle. Classes should be open for extension but closed for modification.
- L - Liskov Substitution Principle. This means that every subclass class should be substitutable for their parent class.
- I - Interface Segregation Principle. Client should not be exposed to methods it doesn’t need. Declaring methods in an interface that the client doesn’t need pollutes the interface and leads to a “bulky” or “fat” interface.
- D - Dependency Inversion Principle. High-level modules should not depend on low-level modules. Both should depend on abstractions.
GRASP principles
GRASP - general responsibility assignment software patterns.
GRASP consists of 5 main and 4 aux principles:
- Information Expert. Assign responsibility to the class that has the information needed to fulfill it.
- Creator. In general, Assign class B the responsibility to create object A if one, or preferably more, of the following apply:
- Instances of B contain or compositely aggregate instances of A
- Instances of B record instances of A
- Instances of B closely use instances of A
- Instances of B have the initializing information for instances of A and pass it on creation
- Controller. The controller should delegate the work that needs to be done to other objects; it coordinates or controls the activity. It should not do much work itself.
- Low Coupling. Coupling is a measure of how strongly one element is connected to, has knowledge of, or relies on other elements.
- High Cohesion. High cohesion means that the responsibilities of a given set of elements are strongly related and highly focused on a rather specific topic.
- Polymorphism. Allows us to perform a single action in different ways.
- Protected variations. The protected variations pattern protects elements from the variations on other elements (objects, systems, subsystems) by wrapping the focus of instability with an interface and using polymorphism to create various implementations of this interface.
- Pure fabrication. A pure fabrication is a class that does not represent a concept in the problem domain, specially made up to achieve low coupling, high cohesion, and the reuse potential thereof derived (when a solution presented by the information expert pattern does not). This kind of class is called a “service” in domain-driven design.
- Indirection. Assign the responsibility to an intermediate object to mediate between other components or services so that they are not directly coupled. The intermediary creates an indirection between the other components
What is KISS / DRY principles?
KISS, an acronym for “Keep it simple, stupid!”. The KISS principle states that most systems work best if they are kept simple rather than made complicated.
DRY, an acronym for “Don’t repeat yourself!”. It means that every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
Explain DDD
DDD stands for Domain-Driven Design, which is a software development methodology that aims to create software that reflects the business domain. The domain is the subject matter of the software application, and DDD is about understanding and modeling the domain to create software that is easier to understand, maintain, and evolve over time.
DDD is based on the idea that the domain is the most important aspect of software development, and that understanding the domain is key to creating successful software. To achieve this, DDD suggests a set of practices that developers can follow, such as creating a common language with domain experts, modeling the domain using domain objects, and organizing the codebase around bounded contexts. There are several key concepts in DDD, including:
- Domain: The subject matter of the software application, which is the primary focus of DDD.
- Ubiquitous Language: A common language shared by developers, domain experts, and stakeholders to understand and communicate the domain.
- Bounded Context: A well-defined boundary around a part of the domain that separates it from other parts of the domain.
- Entities: Objects that have a unique identity and are defined by their attributes and behaviors.
- Value Objects: Objects that are defined by their attributes rather than their identity.
- Aggregates: A cluster of entities and value objects that are treated as a single unit.
- Repository: An object that acts as a mediator between the domain objects and the persistence layer.
- Domain Events: Events that occur within the domain that trigger reactions in the software.
- Context Mapping: The process of defining the relationships between different bounded contexts.
Can you name main OOP principles?
- Abstraction. The aim to simplify and make easy to use are objects through interfaces/abstractions.
- Inheritance. Inheritance is the method of acquiring features of the existing class into the new class.
- Encapsulation. Hiding of internal data and implementation details of the component from other application components. Providing a set of methods to interact with the component (API).
- Polymorphism. Polymorphism means many forms. That means, any object or method has more than one name associated with it. There are two main types of polymorphism:
- Method Overloading(Compile Time Polymorphism) – When more than one method is declared with the same name but with a different number of parameters or different data-type of parameter, that is called method overloading.
- Method Overriding(Runtime Polymorphism) – When more than one method is declared as the same name and same signature but in a different class.
Can you name main programming paradigms?
- Imperative programming paradigm. It works by changing the program state through assignment statements. It performs step by step task by changing state. The main focus is on how to achieve the goal.
- Procedural.
- OOP.
- Declarative programming paradigm. A style of building programs that expresses logic of computation without talking about its control flow. The focus is on what needs to be done rather how it should be done basically emphasize on what code is actually doing.
- Functional programming
- Logical programming
- Mathematical programming
- Reactive programming
- Imperative programming paradigm. It works by changing the program state through assignment statements. It performs step by step task by changing state. The main focus is on how to achieve the goal.
Explain SDLC
The software development lifecycle (SDLC) is the cost-effective and time-efficient process that development teams use to design and build high-quality software.
Main SDLC phases:
- Plan
- Design
- Implement
- Test
- Deploy
- Maintain
Main SDLC models:
- Waterfall
- Iterative
- Spiral
- Agile
Main Agile methodologies:
- Scrum
- Kanban
Git basics
What are the differences between Git Merge and Rebase?
Merge Rebase Git merge is a command that allows you to merge branches from Git. Git rebase allows developers to integrate commits from one branch to another. All the commits are combined as a single commit. All the commits will be rebased and the same number of commits will be added to the branch. Git Merge mostly used with public branches. Git Rebase mostly with private branches. Explain Git Reset and Revert differences.
- git revert. This command creates a new commit that undoes the changes from a previous commit. This command adds new history to the project (it doesn’t modify existing history). Fitting for public branches.
- git reset. It actually does a couple of different things depending on how it is invoked. It modifies the index (the so-called “staging area”). Or it changes which commit a branch head is currently pointing at. This command may alter existing history (by changing the commit that a branch references). Good for private branches.
What are Git Reset types?
- –hard should be easy to understand, it resets(removes) everything
- –mixed (default) :
- unstaged files: don’t change
- staged files: move to unstaged
- commit files: move to unstaged
- –soft:
- unstaged files: don’t change
- staged files: dont’ change
- commit files: move to staged
What is cherry-picking?
Cherry picking in Git means to choose a commit from one branch and apply it onto another.
What is the relation between git pull and git fetch?
git pull = git fetch + git merge
Load Comments